
Was sind „unstrukturierte Dokumente“?
Unstrukturierte Dokumente sind Dateien wie PDFs, Word-Dokumente, Präsentationen oder E-Mails, die keine feste Datenstruktur besitzen. Sie enthalten Texte, Tabellen, Bilder oder Formeln und sind für klassische IT-Systeme schwer auswertbar. Mit AI und Tools wie Docling lassen sich solche Dokumente analysieren, strukturieren und für RAG-Systeme nutzbar machen. So wird verborgenes Wissen zugänglich und kann effizient in Anwendungen eingesetzt werden.
Was ist Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) kombiniert die Leistungsfähigkeit von Large Language Models (LLM) mit externen Wissensquellen, um präzisere und kontextuellere Antworten zu generieren. Dabei werden relevante Informationen aus einer Datenbank abgerufen und mit dem generativen Modell kombiniert, um fundierte Antworten zu liefern. Der Vorteil ist, dass domänenspezifisches Wissen ohne LLM-Neu-Training verfügbar ist, sowie Transparenz und Nachvollziehbarkeit, da Quellen aus den eigenen Daten stammen. Zudem ist so ein besserer Datenschutz gewährleistet, da Daten lokal bleiben können.
Was ist Docling?
Docling ist ein Open-Source-Toolkit von IBM, das Dokumente (PDF, Word, Powerpoint, etc.) strukturiert analysiert, Metadaten wie Seitenzahlen, Tabellen, Bilder und Formeln erhält und daraus sogenannte Docling-Dokumente erstellt. Das erstellte Docling-Document kann nun in andere Formate exportiert werden oder eignet sich wegen der strukturierten Form für die Einbindung in RAG-Systeme und erhöht die Qualität der Abfragen.
Technischer Aufbau des Systems
1. Dokumentenverarbeitung mit Docling:
Der Vorteil von Docling ist es, dass im Gegenteil zu normalen, eingebauten Parsern, die Daten strukturiert extrahiert werden. Dies erleichtert die Integration in AI-Modelle und ermöglicht eine effiziente Verarbeitung in RAG-Systemen.
2. Vektorisierung und Speicherung:
Die extrahierten Daten werden mithilfe von Embedding-Modellen in Vektoren umgewandelt und in einer Vektordatenbank gespeichert. Dies ermöglicht eine schnelle und effiziente Suche nach relevanten Informationen.
3. Generierung von Antworten:
Ein Large Language Model (LLM) wird verwendet, um basierend auf den abgerufenen Informationen präzise Antworten zu generieren. Dabei wurde mithilfe von Benchmarking Wert auf die Minimierung von Halluzinationen und die Sicherstellung der Faktentreue gelegt. Zudem wurden die RAG-Bauteile dank Benchmarking optimiert und zusammengestellt.
One-Day-AI-Agent: Vom Use Case zur AI-Lösung in einem Tag
Theorie ist gut, ein funktionierender AI-Agent ist besser. Mit unserem One-Day-AI-Agent Hackathon entwickeln wir gemeinsam Ihre erste AI-Lösung – massgeschneidert für Ihren Anwendungsfall, integriert in Ihre Umgebung und bereit zum Einsatz.
Kein monatelanges Projektsetup, keine abstrakten Konzepte, sondern ein greifbares Ergebnis, das zeigt, was AI in Ihrem Unternehmen leisten kann. Erfahren Sie mehr über unser Vorgehen von der Ideation bis zur AI-Lösung.
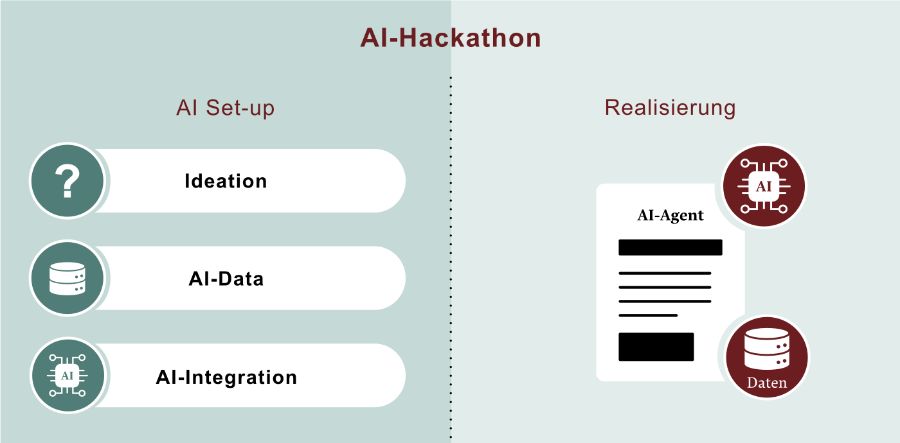
Beurteilung des Erreichten
Während des Praktikums konnte ich alle Kernziele des Projekts erfolgreich umsetzen. Das RAG-System funktioniert stabil und ermöglicht ein zuverlässiges Retrieval (Informationssuche und -abruf aus Dokumenten) relevanter Dokumententeile.
Die projektbasierte Wissensumgebung wurde aufgebaut, die Dokumente korrekt in Chunks zerlegt und in der Vektordatenbank gespeichert, sodass Abfragen effizient beantwortet werden können.
Docling wurde umfassend getestet und liefert strukturierte Dokumente zuverlässig, inklusive Metadaten, Tabellen, Überschriften und logischer Reihenfolge.
Damit konnte die Machbarkeit für interne sowie potenzielle Kundenprojekte demonstriert werden. Alle wichtigen Limitationen, wie Sprachunterstützung des LLM, die Verarbeitung besonders komplexer PDFs und die derzeitige Python-Exklusivität von Docling, wurden dokumentiert und bilden die Grundlage für zukünftige Optimierungen.
Insgesamt konnte ein funktionierender Proof of Concept (PoC) erstellt werden, der die geplanten Ergebnisse erfolgreich abbildet.
Reflexion: AI-gestützte Dokumentenverarbeitung im realen Einsatz
Besonders positiv hervorzuheben ist, dass das RAG-Setup lokal nutzbar ist, was Datenschutz und Kontrolle über interne Daten gewährleistet.
Docling zeigt sich als stabiles und leistungsfähiges Werkzeug mit grossem Potenzial als Standard-Parser für AI-gestützte Dokumentenverarbeitung. Die konkreten Use Cases und die Machbarkeit der Implementierung wurden durch das Praktikum greifbar und nachvollziehbar.
Einige Herausforderungen, wie die Verarbeitung sehr grosser oder komplexer Dokumente, boten die Gelegenheit, effiziente Strategien für Chunking und Performance-Optimierung zu entwickeln. Gleichzeitig ermöglichte die Arbeit mit unterschiedlichen LLMs wertvolle Einblicke in Modellstärken und -einschränkungen, insbesondere hinsichtlich Sprachunterstützung.
Schlussfolgerungen und Ausblick
Die Kernziele des Praktikums wurden erfolgreich erreicht und der PoC umfassend dokumentiert.
Nächste Schritte könnten die Integration des Systems in ein reales Kundenprojekt, die Nutzung eines stärkeren LLMs mit verbesserter Sprachunterstützung sowie die Beobachtung der Entwicklung von Docling-Java sein. Darüber hinaus könnten alternative LLMs wie Apertus oder GPT-OSS für Benchmarking und Vergleich herangezogen werden.
Für Deimos dient das Projekt als Entscheidungsgrundlage für den Technologieeinsatz und ermöglichen Zeit- sowie Risikoeinsparungen bei künftigen Projekten.